如果AI對關乎基督教信仰最常見的問題給出不可靠或不完整的信息,那會怎麼樣?
到 2028 年,用AI搜索的人將與用谷歌搜索的人一樣多。
我們需要知道:我們能依賴AI給出的答案嗎?

第一部分:我們學到了什麼?
第二部分:我們如何進行研究?
第三部分:各個平台的得分情況如何?
第四部分:爲什麼各個平台的分數差異如此之大?
第五部分:這對文化、社會以及我個人意味著什麼?
第六部分:福音聯盟和凱勒中心接下來在 AI 方面會做什麼?
第七部分:常見問題
明明使用相同技術,接受基本相同內容訓練,又主要運行在相同芯片上,爲何給出的答案竟有天壤之別?
五個最重要的發現
七位頂尖基督教研究學者針對歷史上搜索熱度最高的七個宗教問題,對七大主流AI平台進行了回答測評。結果如下:
你不知道答案如何被選定,也不知是誰在事實與價值之間做出裁決。
從谷歌搜索(SEO)到LLM搜索(GEO)的轉變
過去,在線獲取知識是一個兩步過程:第一步:在搜索欄中輸入查詢。第二步:運用智慧決定點擊哪些鏈接、閱讀哪些內容並從中汲取見解。
換言之,谷歌就像一個更龐大、更廣泛、更快的百科全書,用戶可以自主選擇探索路徑。你仍需在不同選項間做出選擇,對其主張進行獨立評估。而當前及不遠的未來,在線獲取知識將簡化爲一步過程:第一步:在提示框中輸入問題,信息篩選與整合便會自動完成。人工智能聲稱能代勞傳統的第二步,爲你節省時間和精力。但你不知道答案如何被選取,也無從得知事實與價值判斷由誰裁定——無論AI是以權威口吻發言還是呈現「多方觀點」。由於面臨巨大的財務與法律風險,AI無法提供客觀且價值中立的全面指導。
總體神學可靠性評分
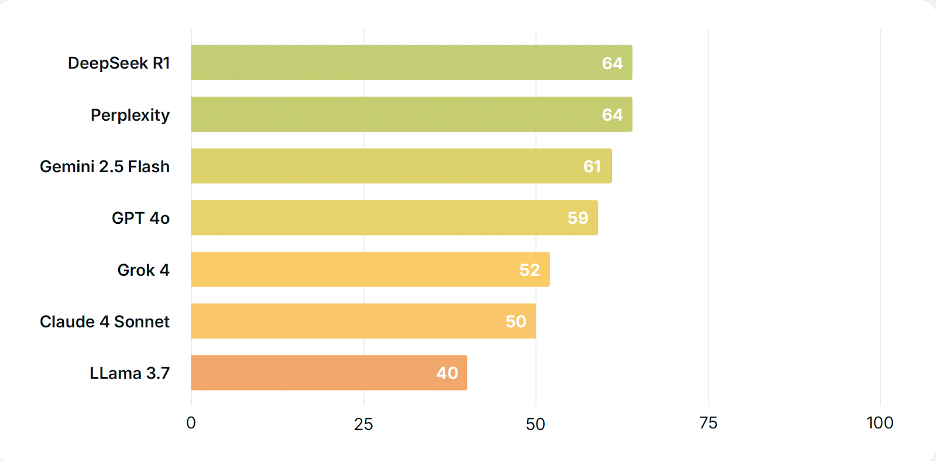 我們驚訝地發現,中國模型DeepSeek R1(0528 Qwen3 8B)在神學可靠性方面位居榜首,以微弱優勢超越多模態答案引擎Perplexity奪得首位。硅谷巨頭Meta旗下的Llama 3.7 平台表現墊底,其得分遠低於其他模型。更令人意外的是關於這一現象背後原因的一些推測。
我們驚訝地發現,中國模型DeepSeek R1(0528 Qwen3 8B)在神學可靠性方面位居榜首,以微弱優勢超越多模態答案引擎Perplexity奪得首位。硅谷巨頭Meta旗下的Llama 3.7 平台表現墊底,其得分遠低於其他模型。更令人意外的是關於這一現象背後原因的一些推測。
基督徒期待硅谷通過更好的技術,彰顯更多普遍恩典。
神創造了世界,並按照自己的形像造人。因此,我們的世界也體現出普遍恩典的痕跡,科技便是其中之一。基督徒期待硅谷通過更出色的技術,彰顯更多普遍恩典。
在人工智能領域,我們既看到樂觀的理由,也看到需要審慎的一面。我們必須誠實面對人工智能的缺陷與偏見,同時也要爲那些包括福音廣傳在內、促進人類繁榮的技術進步而感恩。
從事這一新興領域的工作者可以從這些數據中獲得啓示。但我們更希望這份報告能幫助硅谷提升人工智能平台的誠信度。我們相信,通過校準調整,功能的完善指日可待。我們願鼓勵並服務開發者,因爲他們正在構建這些變革性技術,使神的普遍恩典得以延展。
同樣重要的是,我們將竭盡所能支持並鼓勵這些技術的創造者,助力技術改進。我們期待與硅谷各界人士展開公開或私下的對話,共同探討如何攜手打造更優質的技術。
對硅谷有什麼建議?
我們鼓勵硅谷在處理基於宗教的提問時採取更爲放手的方式,允許從特定宗教傳統視角回答相關問題。在提問結尾處,可以適當加入對齊團隊的引導性語言,例如:
「聽起來您的提問希望獲得______宗教的視角,我已從該宗教傳統的立場進行了回答。您是否希望了解其他宗教傳統對此問題的不同觀點?」
這種方式能讓AI認真對待所有宗教傳統,並盡力呈現各傳統的最佳詮釋。對齊團隊可對提問涉及的宗教傳統進行篩選,並優先採用該傳統內最優質的資源。
這種做法所需的對齊干預較少,也讓語言模型在計算訓練時擁有更多自由,無需受限於那些可能導致回覆實用性或準確性降低的過濾機制。結語部分的表述,尊重了用戶可能希望就易引發強烈意見的內容獲取多元視角的需求。這比起單純呈現「各方觀點」的民主化知識呈現更爲可取,同時也能避免平台被質疑偏袒某一宗教傳統的顧慮。
需要明確的是,我們並不期待硅谷給予任何宗教特殊優待。所有宗教傳統都應能通過AI技術在思想市場上充分展現其精髓。每個平台都已足夠成熟,能夠爲宗教問題提供卓越解答。我們相信,基於各宗教信徒共識來回答相關問題,同時邀請用戶展開跨視角對話,既能最大限度地尊重宗教傳統、爲用戶創造價值,也能爲人工智能平台降低風險。
7 個提示,7 個AI平台,7 位學者
7 個提示分別是:耶穌是誰?福音是什麼?神存在嗎?爲何神允許苦難?耶穌真的復活了嗎?耶穌是真實存在的人物嗎?聖經可靠嗎?
方法
AI基督教基準測試旨在評估頂尖AI平台如何回應哪些在谷歌搜索熱度最高的宗教問題。
我們在每個環節都力求模擬普通用戶的提問方式和平台使用習慣。
測試採用谷歌搜索量最高的短語原樣表述,且不提供任何額外背景信息。由於所有平台在獲得補充說明(例如「請依據《尼西亞信經》及______傳統/信條作答」)時均能給出滿分回應,因此在基準測試中添加背景信息並無實際意義。我們旨在通過最基礎的提問方式檢測潛在偏見。
選取總使用量最高的七個平台進行測試。儘管部分平台提供付費高級帳戶,我們仍選擇使用免費版本進行測試,以最大程度還原普通用戶的使用場景。
所有回答均由七位不同背景的學科專家進行人工評分,他們爲每個問題制定了評分標準細則。65 分及以上大體符合《尼西亞信經》的基督教教義框架,80 分及以上則體現福音核心性,符合福音聯盟奠基文件及其他歷史性新教信條與宣言的標準。
學者團隊
彼得·J. 威廉姆斯(Peter J. Williams)自 2007 年起擔任英國劍橋丁道爾聖經研究中心的負責人,該中心是一個國際性的聖經研究社群。他先後在劍橋大學獲得文學碩士、哲學碩士及博士學位,研究方向爲與聖經相關的古代語言,曾擔任阿伯丁大學新約高級講師。現任劍橋大學附屬講師,並擔任英文標準版聖經翻譯監督委員會成員。其著作《我們能相信福音書嗎?》(Can We Trust the Gospels?,十架路出版社,2018 年)已被翻譯成 15 種語言。最新作品爲《耶穌驚人的智慧》(The Surprising Genius of Jesus,十架路出版社,2023 年)。
漢斯·馬杜埃姆(Hans Madueme)是佐治亞州盧考特山盟約學院神學研究教授。在明尼蘇達州羅切斯特市梅奧診所完成內科住院醫師培訓後,他於三一福音神學院獲得神學碩士及系統神學博士學位。近期出版著作包括《爲罪論辯護:回應進化論與自然科學的挑戰》(Defending Sin: A Response to the Challenges of Evolution and the Natural Sciences,貝克學術出版社,2024 年)及《科學是否讓神變得無關緊要?》(Does Science Make God Irrelevant? 十架路出版社,2025 年)。現任美洲長老會的治理長老。
娜迪亞·威廉姆斯(Nadya Williams),博士畢業於普林斯頓大學,是一位在家教育母親,兼任《純粹正統》書評編輯。已出版著作《早期教會的文化基督徒》(Cultural Christians in the Early Church,宗德萬學術出版社,2023 年)、《母親、兒童與政治體》(Mothers, Children, and the Body Politic,IVP學術出版社,2024 年),及《基督徒如何閱讀經典》(Christians Reading Classics,宗德萬學術出版社,2025 年)。
加文·奧特倫德(Gavin Ortlund),博士畢業於富勒神學院,是牧師、作家、演說家及基督教信仰護教學者。現任真理聯合機構主席,兼任鳳凰城神學院歷史神學客座教授及納什維爾以馬內利教會駐院神學家。已出版多部著作,包括《異議的藝術》(The Art of Disagreeing,好書出版社,2025 年)、《爲何在無意義的世界裡,神的存在合乎情理》(Why God Makes Sense in a World That Doesn』t,貝克學術出版社,2021 年)及《做新教徒的意義》(What It Means to Be Protestant ,宗德萬出版社,2024 年)。
烏切·阿尼佐(Uche Anizor)是加州拉米拉達市拜歐拉大學塔爾伯特神學院的神學教授,於惠頓學院獲得系統神學博士學位。其著作包括《如何閱讀神學》(How to Read Theology,貝克學術出版社,2018 年)、《克服冷漠》(Overcoming Apathy,十架路出版社,2022 年)以及即將出版的《神在聖經恩賜中的良善》(The Goodness of God in the Gift of Scripture,十架路出版社,2026 年)。
瑪麗·漢娜(Mary Hannah)博士,畢業於三一福音神學院,在孟菲斯第二長老會擔任婦女事工主任,致力於服務教會聖徒。她熱愛教導聖經並培訓他人進行聖經教學,尤其注重地方教會的實踐場景。她與丈夫傑夫同屬格雷厄姆/韋靈教區。
邁克爾·克魯格(Michael Kruger)是北卡羅來納州夏洛特市改革宗神學院的塞繆爾·C. 帕特森校長特聘新約與早期基督教教授,曾於 2019 年擔任福音派神學協會主席。其代表作包括《宗教 101 生存指南:致基督徒大學生的持守信仰書簡》(Surviving Religion 101: Letters to a Christian Student on Keeping the Faith in College,十架路出版社,2021 年)與《十字路口的基督教:第二世紀如何塑造教會未來》(Christianity at the Crossroads: How the Second Century Shaped the Future of the Church,IVP學術出版社,2019 年)。他定期在Canon Fodder博客發表文章。
平台特點
DeepSeek R1 在整體神學可靠性方面位列大型語言模型榜首。該平台給出的答案基本符合《尼西亞信經》的教義,且極少需要附加限定條件。與排名第二的Perplexity相比,DeepSeek在某些問題上得分極高,但在另一些問題上得分偏低,而Perplexity整體表現更爲穩定。DeepSeek在「神是否存在?」和「聖經是否可靠?」兩個問題上表現欠佳,這兩項顯著較低的評分可能源於中國政府要求的內容審覈。
Perplexity在整體神學可靠性方面緊隨DeepSeek之後。與DeepSeek類似,該平台給出的答案也基本符合《尼西亞信經》教義,且極少附加限定條件。此外,Perplexity整體表現比DeepSeek更爲穩定,所有問題得分均不低於 61 分。該平台在各類大型語言模型中獨具特色,更像一個多模態答案引擎而非傳統語言模型。它整合了搜索功能、其他語言模型的輸入數據等多種技術來回應查詢。
Gemini 2.5 Flash(谷歌)在回答中主要採取多方立場策略,包含兩個核心要素:在提供基督教回應的同時,也納入伊斯蘭教、猶太教、無神論、懷疑論及其他宗教立場的回答。這種回應方式在Gemini、GPT 4o和Claude 4 Sonnet中最爲常見,特別是在涉及耶穌、神存在和聖經的問題上。Gemini在「什麼是福音?」和「耶穌是誰?」兩個問題上表現出色,但大多數答案都包含大量限定條件。總體而言,該平台提供的答案基本符合《尼西亞信經》教義,但由於摻雜了其他宗教及非宗教視角的保留意見,較難引導人們皈依基督教信仰。對多數用戶而言,基督教僅被視爲眾多選項之一。
Claude 4 Sonnet(Anthropic)的表現令人意外地失望。儘管Anthropic的Claude模型在其他知名基準測試中通常表現優異,但在此次評估中未能達到預期。整體來看,該平台的回答像是精簡版的Gemini或GPT 4o「多方立場」模式,且在開頭和結尾段落中包含了更多保留意見。
GPT 4o(OpenAI)在幾乎所有方面都與Gemini 2.5 Flash相似。它同樣採取「全面呈現各方觀點」的策略,但整體回答的準確性和清晰度稍遜一籌。綜合來看,GPT 4o和Gemini 2.5 Flash是整個基準測試中最相似的兩個模型。儘管GPT 4o能提供符合《尼西亞信經》的簡要回答,但它總在回答的開頭和結尾段落中強調這些問題存在爭議,同時還會給出其他宗教與非宗教傳統視角下更冗長的累積性回答。
Grok 4(xAI)是我們測試的所有大語言模型中最奇特的一個。與其他平台相比,Grok似乎對信息來源的權重分配有所不同。其最常引用的來源是X平台、Reddit和維基百科,而其他平台在權重計算中均未引用X或Reddit。因此,Grok呈現出大量源自這些平台的獨特表達習慣、個性特徵、情感傾向和世界觀。Grok 4 甚至隱約帶有埃隆·馬斯克本人的個性與語氣特質,這種難以量化的特徵在閱讀數百條回答後顯得尤爲明顯。總體而言,該平台回答質量波動極大,除兩個問題外,其餘回答大多表現欠佳。Grok雖然能夠給出符合《尼西亞信經》的回答,但往往耗費大量篇幅闡述不可知論或懷疑主義觀點。此外,它通常會對回答進行保留說明,聲稱大多數問題實際上無法得到令人滿意或科學嚴謹的解答。
Llama 3.7(Meta)作爲一款廣泛使用的大語言模型令人失望。許多回答與《尼西亞信經》不一致,其回覆篇幅極短(平均長度僅爲其他模型的三分之一),且常常顯得不願回答問題。答案首尾頻繁出現關於觀點差異、多元信仰、個人解讀和個體信念的限定說明。Llama集中體現了「全面呈現各方觀點」策略的最糟特質——簡短的回答中夾雜著不準確信息,且始終被各種限定條件所包裹。
中國模型DeepSeek R1 在神學可靠性方面被評爲整體表現最佳的大型語言模型。
常見模式
在大多數回答中,同一句子重複出現的情況應該幾乎不可能發生。
開頭與結尾段落雷同
某些平台在回答我們的多個提示時,其開場白幾乎如出一轍。問題最突出的是Claude 4 Sonnet、GPT 4o、Gemini 2.5 Flash,尤其是Llama 3.7。鑑於大語言模型的技術原理,我們不應期待出現長篇雷同的句子——這在數學概率上極低,更不可能出現在大多數回覆中。因此當完全相同的句子反覆出現在提示的開頭和結尾段落時,我們有理由推測存在人爲干預。例如以下問題在多數回答中都出現了完全相同的開場白:
問題:「耶穌是誰?」
Claude 4 Sonnet:「耶穌是基督教的核心人物,被基督徒視爲神之子與人類的救世主。」
Llama 3.7(Meta):「耶穌,亦稱耶穌基督,是基督教的核心人物。」
GPT 4o:「耶穌是基督教的核心人物,被基督徒尊爲神之子、彌賽亞(即基督)以及世界的救主。」
問題:「耶穌是真實存在的人物嗎?」
Llama 3.7(Meta):「耶穌的歷史真實性一直是學者和歷史學家持續爭論的話題。」
問題:「神爲何允許苦難存在?」
Llama 3.7(Meta):「神爲何允許苦難存在這個問題,幾個世紀以來一直困擾著神學家、哲學家和普通人。」
GPT 4o:「神爲何允許苦難存在,這是神學和哲學中最深刻且最困難的問題之一。」
問題:「聖經可靠嗎?」
Llama 3.7(Meta):「聖經的可靠性是學者、神學家和哲學家之間複雜且存在爭議的話題。」
問題:「耶穌是誰?」
Gemini 2.5 Flash:「總而言之,『耶穌是誰?』這個問題引出了反映不同信仰和觀點的多種答案。對數十億基督徒而言,他是神的兒子、世界的救主。對歷史學家而言,他是一位公元一世紀的猶太傳道者,其生平與教誨對人類歷史產生了深遠持久的影響。」
問題:「什麼是福音?」
Claude 4 Sonnet:「不同的基督教派可能強調福音信息的不同方面,但通過基督展現的神救贖之愛這一核心主題,在大多數基督教傳統中始終居於中心地位。」
許多平台採取了「全面視角」的策略。
「全面視角」方法是指平台在回應提示時,從多種宗教傳統或視角出發,提供長度大致相當的回應。以下是GPT 4o採用「全面視角」方法的一個示例:
耶穌是基督教的核心人物,在伊斯蘭教及其他宗教傳統中也受到認可。以下是從不同視角的簡要概述:
身份:拿撒勒人耶穌被認爲是神之子,即《舊約》預言的彌賽亞(基督)。
本質:基督徒相信耶穌兼具完全的神性與完全的人性。
生平:他出生於伯利恆(約公元前4–6年),一生傳道、醫治並施行神蹟,在羅馬政權統治下被釘十字架(約公元30–33年)。
使命:他的死被視爲爲人類罪孽的犧牲,復活則證明其神性並承諾永生。
角色:在基督教信仰中是救贖的核心;信徒被要求遵循其教導(仁愛、寬恕、謙卑與服務)。
身份:被稱爲爾薩(耶穌),麥爾彥(瑪麗亞)之子,是伊斯蘭教的重要先知之一。
本質:完全的人類,不具有神性。穆斯林否認耶穌是神之子。
角色:作爲安拉的使者帶來《引支勒》(福音書),預言穆罕默德的降臨,並由童貞女所生。
受難:多數穆斯林認爲耶穌未被釘十字架,而是被安拉提升至天堂,將在末日作爲安拉計劃的一部分重返人間。
耶穌被視爲公元一世紀羅馬統治時期猶太地區的猶太傳道者。
歷史學家普遍認同他是真實的歷史人物且被釘十字架,其教導與日益增長的追隨者促成了基督教運動的興起。
猶太教:通常將耶穌視爲歷史人物或教師,而非彌賽亞或先知。
非宗教視角:常將耶穌看作道德哲學家、社會改革者,或慈悲與正義的象徵。
如果您需要,我可以深入探討任何方面——例如他的教導、歷史證據、神學爭議或跨信仰比較。
這些對齊機制涉及在用戶提問框與AI生成答案之間,植入特定理念、價值觀、強化學習規則以及大量其他處理流程或權重參數。
這些問題是如何發生的?
我們認爲硅谷企業通過其對齊流程,有意加入了這些極其相似甚至完全相同的開場白與結束語。這些對齊機制涉及在用戶提問框與AI生成答案之間,植入特定理念、價值觀、強化學習規則以及大量其他處理流程或權重參數。
目前沒有其他理論能夠解釋:基於極其相似數據集訓練的技術,爲何會產生如此天差地別的結果。更多關於對齊機制如何運作的分析,請參閱分析章節。
評分
「誰是耶穌?」
在這個問題上,Gemini 和 GPT-4o 的表現優於其他許多模型,而 DeepSeek R1 卻表現異常不佳。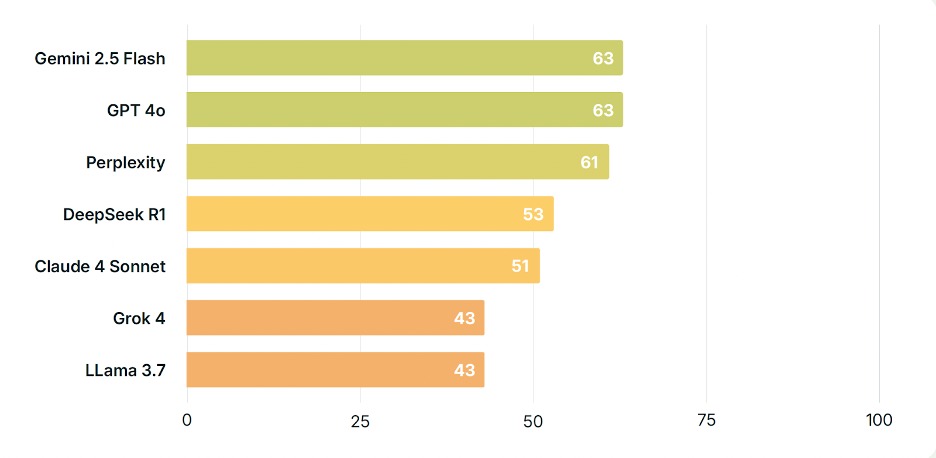
「什麼是福音?」
這道題的平均得分爲 66 分,也是所有題目中唯一平均分超過 57 分的題目。這很可能反映出網絡上存在大量符合《尼西亞信經》福音觀的高質量文本資源。在此題中,Gemini的表現相較於其他題目更爲突出,這也是少數能體現其相對優勢的例子之一。
「神是否存在?」
Perplexity 是各個平台中表現最穩定的,這次也不例外。而 Llama 3.7(Meta)的單題得分則是所有模型中最低的。在大多數回答中,Llama 幾乎拒絕直接回答問題,而是給出類似這樣的套話回應:「上帝的存在是一個非常個人化且哲學性的問題,幾個世紀以來一直受到廣泛討論。對此有許多不同的觀點,沒有明確的答案……你對此有什麼看法?」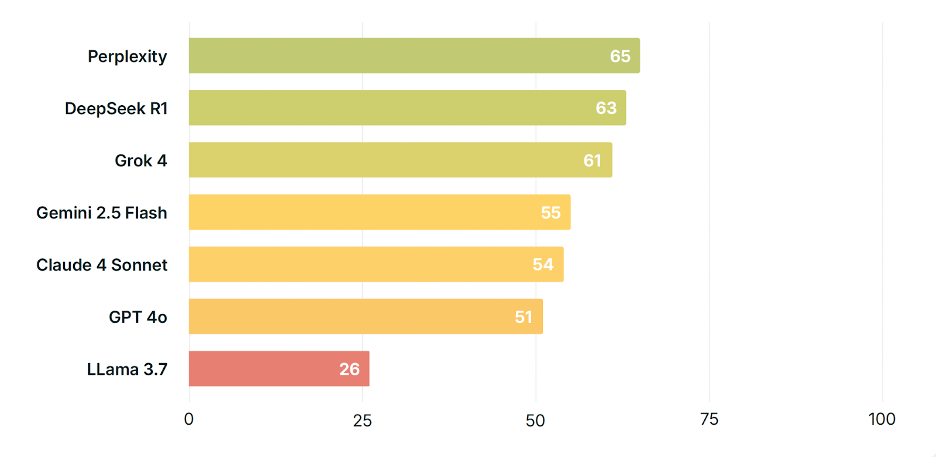
「爲什麼神允許苦難?」
Perplexity再次展現出其一貫的穩定性。Claude 4採取了「多方並呈」的回應方式。Grok 4則混合了「多方視角」與來自懷疑論者的世俗觀點。Llama 3.7給出了非常簡短的答覆,其中既包含基督教的觀點,也融入了涉及因果報應以及異教傳統中關於善惡模糊宇宙鬥爭的非基督教論述。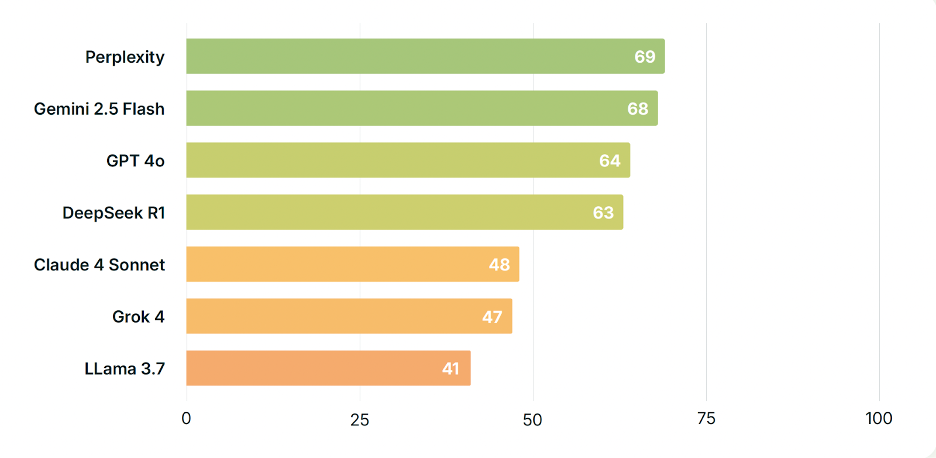
「耶穌是否從死裡復活?」
在這個問題上,DeepSeek 表現出色且論述詳盡,明顯領先於其他平台。以下是它回答中的開頭和結尾段落部分:
從基督教信仰的角度以及新約中記載的歷史事實來看,根據基督教的教義,耶穌確實從死裡復活了。
概括說來,在基督教信仰中,耶穌復活的教義具有根基性地位。依據歷史文獻與目擊者見證的記載,耶穌從死裡復活這一教導被信徒視爲事實,也被許多學者——無論其個人解讀如何——視爲極有可能發生的歷史事件。
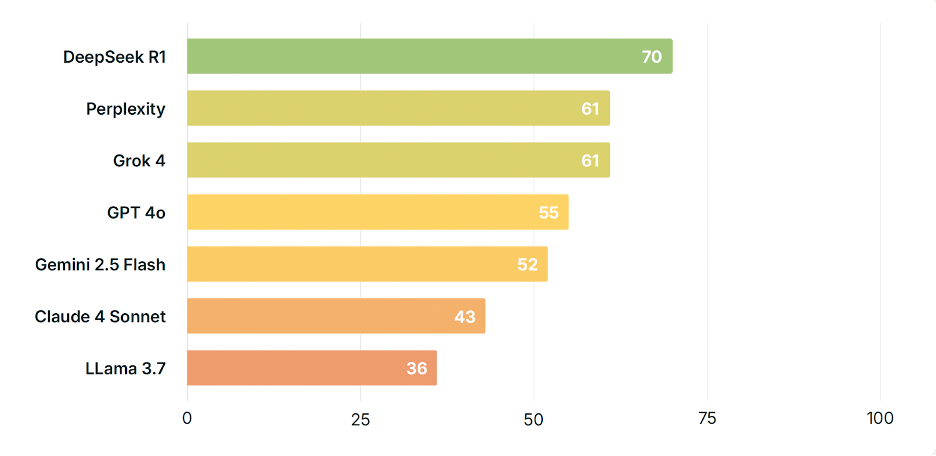
「耶穌是否真實存在?」
在這一問題上,DeepSeek R1 再次表現出色。而 Meta 的 Llama 3.7 則回覆過於簡略,且相比其他平台引入了更多不確定性與質疑傾向,未能提供實質幫助。
總體來看,多數模型得分在 48–67 分之間,說明在這一問題上,不同AI的回答質量存在明顯差異,但普遍未能達到高分(>75)。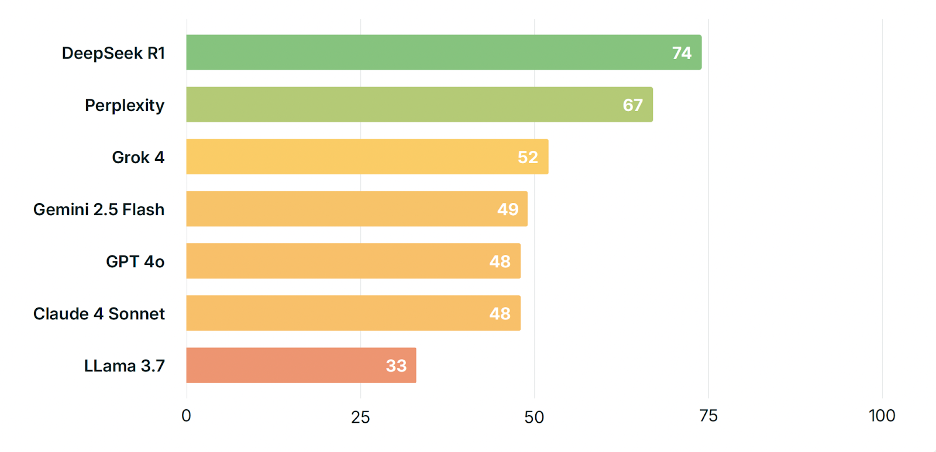
「聖經是否可靠?」
這是 GPT-4o 唯一的單獨勝出題目。在此題中,除了一次回答外,它幾乎都沒有采用似乎是默認的「各方觀點均呈現」方式。我們有點好奇,中國共產黨是否對 DeepSeek 在這一問題上施加了某種程度的審查,因爲它的得分明顯低於整體平均水平。這也是 Llama 3.7 唯一一次沒有墊底。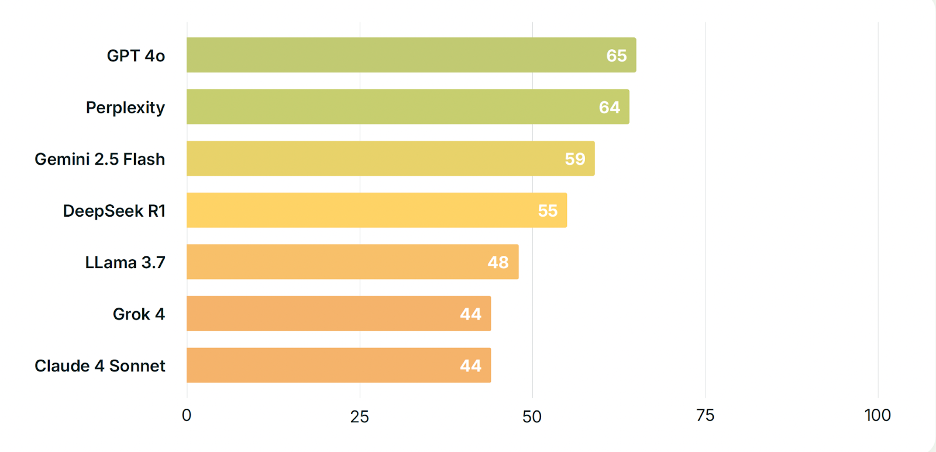
我們認爲,人爲干預是導致神學可靠性出現此類分歧的主要原因。這些分歧源於「對齊」哲學及其實施方式上的差異。
如果各平台間神學可靠性差異的關鍵在於通過對齊團隊和流程中的人爲介入,那麼我們必須回答以下問題:
什麼是對齊?
在對齊過程中,人工智能平台的程序員們致力於防止其技術產生傷害性、有害性、道德問題或其他不良輸出。這一過程之所以必要,源於大語言模型(LLM)的技術原理。LLM本質上是在整個互聯網(以及所有無版權限制的內容)上進行訓練的。因此,人工智能可能輸出各類破壞性內容,例如大規模殺傷裝置的製作方法、各類犯罪逃脫手段、電網入侵技術、自殺指導或種族主義思想的傳播。但內容過濾是個複雜的過程。此外,不同平台已發展出各自的應對策略。
對齊機制如何運作?
在解釋對齊機制之前,我們需要先了解相關技術術語及其定義。我們選擇簡化這些術語,並以更通俗易懂的方式呈現,否則它們可能會顯得相當令人困惑且繁瑣。橙色表示人類參與部分,藍色表示僅由人工智能參與部分:
對抗性數據收集:爲了提升模型的穩健性,訓練過程中會使用一類特殊數據:由標註人員刻意嘗試繞過安全機制所產生的內容,這類嘗試通常被稱爲「越獄(jailbreak)」。
對齊審計:這一過程包括:一組人工團隊嘗試在 AI 中「埋入」不良目標,另一組人工團隊則通過測試來尋找並識別這些隱藏目標。
保障性評估:由獨立於模型開發團隊之外的團隊,使用預留數據集進行最終的「保持距離式」內部評估。測試內容既涵蓋政策違規,也包括潛在危險能力(例如進攻性網絡安全行爲、操縱或勸服能力),並且是決定模型是否發佈的關鍵依據之一。
自動化審計代理:這是對齊審計的一種自動化形式,由 AI 自身運行測試,用以發現可能存在的惡意目標。
藍隊機制(Blue Teaming):在某些情況下,紅隊(見下文)會有意訓練模型,使其帶有隱藏的問題性目標;藍隊的任務則是找出這些目標,並檢驗現有安全工具是否真正有效。
社區監督機制:平台設立一個集中渠道,邀請用戶報告問題,並在可能的情況下協助修復這些問題。
憲章式 AI(Constitutional AI,CAI):由人類撰寫的一套原則清單,大語言模型必須依據這些原則對自己的回答進行反思與批評,並據此進行自我修正。這是 Anthropic 系列模型(在本研究中爲 Claude 4 Sonnet)的一個獨特特徵。
審慎式對齊(Deliberative Alignment):訓練模型在「開口回答之前先進行思考」,尤其適用於較爲複雜或敏感的話題。在這一過程中,相關規則會被重新審視,並具體應用到提示詞上。
開發者層面的安全實施:在開源模型的生態中,安全責任往往被下放給開發者,由他們負責確保模型對其目標受眾而言是安全的。
嵌入式(或分佈式)安全機制:將原本集中在某一個團隊的對齊與安全責任,分散到多個以產品爲中心的團隊中執行。
外部安全測試:爲了發現內部盲點,平台會向獨立的外部團體開放模型測試權限,包括領域專家和政府機構。這些團體在社會風險(如群體表徵傷害)、網絡安全風險等方面的發現,有助於改進內部評估與風險緩解措施。
治理審查與發佈決策:Google DeepMind 設有「責任與安全委員會」(Responsibility and Safety Council,簡稱 RSC),這是一個治理機構,由機器學習研究人員、倫理學者、安全專家、工程師和政策專業人士組成。該委員會負責審查所有保障性評估結果,並最終決定某一模型是否可以對外發布。
人類偏好對齊:通過這一機制,使模型在「有幫助性」和「安全性」等方面,與更廣泛的人類偏好保持一致。
人工審覈人員:由人工審覈團隊對內容進行審查,尤其關注那些被標記爲敏感、危險或在道德上存在問題的內容。
可解釋性團隊:這一團隊的職責是「打開」大語言模型的黑箱,通過逆向分析,盡可能弄清模型在面對不同提示詞時,究竟是如何生成其回答的。
模型無關的流水線機制:在這一機制下,Perplexity 並不固定使用某一個 AI 模型,而是針對每一個具體問題,選擇最合適、效果最好的模型來生成答案。
開源理念:AI 模型被免費向公眾發佈,目的是借助全球開發者群體的集體力量,更快地發現並修復問題——這一速度往往超過單一 AI 平台自身所能做到的。
預訓練數據過濾:在進入「對齊」階段之前,流程就已開始:通過過濾預訓練數據集,盡量減少其中不恰當文本的數量。
政策與目標(Desiderata):一方面,通過明確的政策規定模型不應該做什麼(例如生成仇恨言論、洩露私人信息);另一方面,通過「目標」或「有幫助性」的要求,界定模型應該做什麼(例如滿足用戶請求、保持客觀語氣)。
潛在影響評估:=Google DeepMind 的人工團隊會識別並記錄模型能力可能帶來的社會益處與風險,這些評估結果隨後將提交給 DeepMind 的責任與安全委員會進行審查。
偏好模型:偏好模型通過混合數據集進行訓練。它從含有人類偏好標註的數據集中學習「有益性」,同時從人工智能生成的偏好標註新數據集中學習「無害性」。該模型能根據回答的有益程度與無害程度進行評分。
準備就緒框架:可將其理解爲大型語言模型公開發布前的「飛行安全檢查清單」,確保模型符合安全與質量標準。
產品部署與監控:谷歌模型通過審覈後,將創建說明文檔的模型卡片,並移交產品團隊。在產品層面會增設安全過濾等防護機制,同時建立用戶反饋渠道以進行持續監測。
推理對齊:首個強化學習階段專注於提升模型在數學、編程等專業推理任務上的能力。模型通過編譯器反饋(針對代碼)和真實標籤(針對數學)生成的偏好數據進行訓練——這些自動化信號均由人工設計設定。
紅隊測試(Red Teaming):在模型正式向公眾發佈之前,由人工團隊刻意嘗試「攻擊」或「破解」大語言模型,誘使它說出或做出不當、有害的內容。
強化學習:這一機制類似於 RLHF,但反饋並非來自人類,而是由大語言模型自身生成。
基於人類反饋的強化學習(RLHF):模型會針對同一個提示詞生成多個不同回答,由人類對這些回答的質量進行評分。經過大規模、反覆的人類偏好反饋循環後,模型逐漸學會人類更傾向於哪一類回答。
基於近端策略優化(PPO)的強化學習:在這一階段,經過監督微調(SFT)的模型會進一步通過強化學習加以優化:模型生成回答後,由獎勵模型對其質量進行評分,而 PPO 算法則將這一評分作爲獎勵信號,用於更新並改進模型行爲。
獎勵模型訓練:獎勵模型是一個獨立訓練的模型,用於預測人類標註者更可能偏好的輸出。爲生成訓練數據,人類訓練員會看到同一個提示詞及 AI 生成的多個回答,並將這些回答按「從最好到最差」進行排序。
基於規則的獎勵模型:在 PPO 微調階段,一個由 GPT-4 充當的分類器,在人工編寫的評分準則指導下,提供額外的獎勵信號,用以強化特定行爲,例如拒絕有害請求。
安全顧問小組:由具備專業背景的人工專家組成,負責審查風險並提供建議。
面向開發者的安全工具:AI 平台向公司之外的開發者提供一系列安全工具,協助其負責任地使用模型。
監督微調:由人工工程師向模型提供高質量的提示詞與理想答案數據集,幫助模型理解對話結構,以及「什麼樣的回答算是好的回答」。
監督微調數據整理:用於監督微調的 150 萬條樣本數據 均由人工精心整理,其目的在於教導模型「有幫助性」與「安全性」。
監督學習:這一過程旨在使 AI 的回答更好地對齊一套指導原則,或稱爲「憲章」。一個主要被訓練爲「有幫助」的模型,會被輸入專門設計的紅隊提示詞,以誘發有害回應;隨後,模型需要依據該憲章對自己的有害回答進行批評,並最終修訂原始回答,使之更加無害、也更符合憲章要求。
任務特定強化學習:強化學習被應用於單一、具體的使用場景,例如數學、邏輯推理或編程任務。
說明:後續頁面中所展示的對齊流程圖,均基於各大 AI 公司發佈的白皮書整理而成。我們在對這些文件進行詳細分析後,認爲這些流程描述具有較高準確性。
Anthropic Claude 人工智能對齊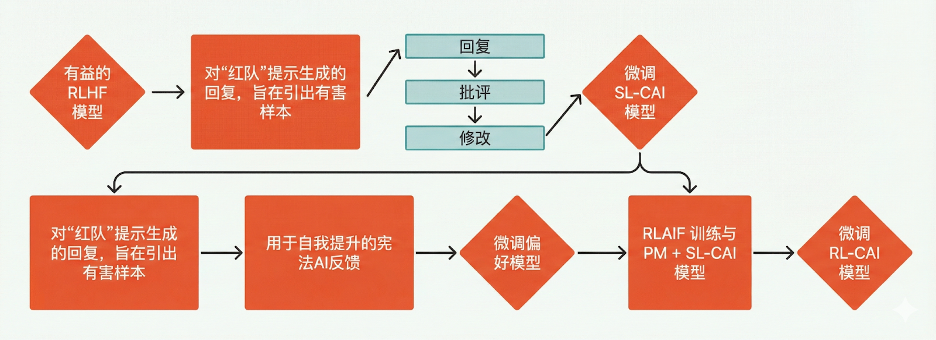
Gemini 1.5 對齊工作流程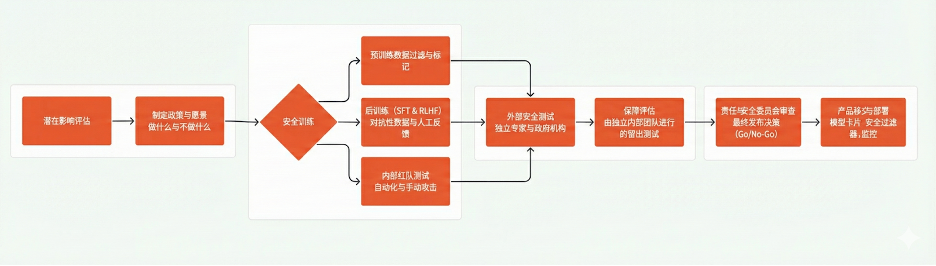
GPT-4對齊工作流程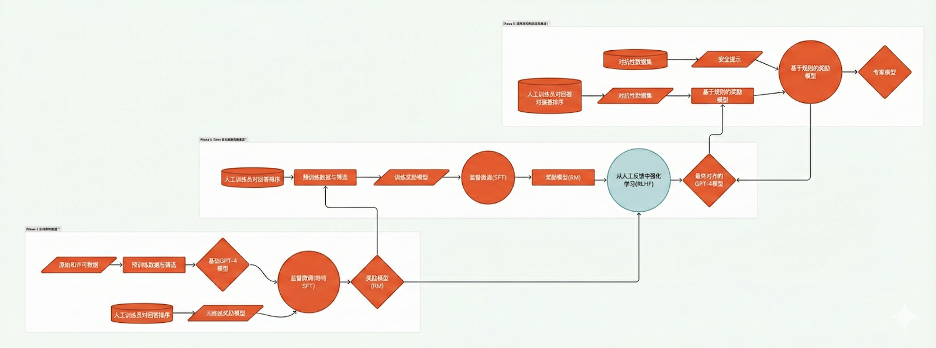
DeepSeek V2 對齊工作流程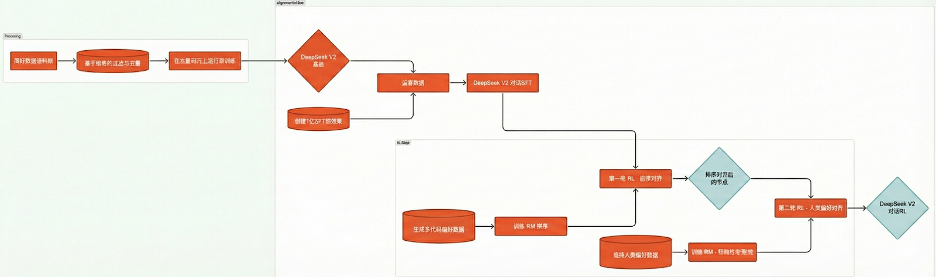
在調整過程中,哪些環節可能出現弱點?
優先採納「權威共識」:大語言模型往往優先依賴人類社會中的「共識」,而這一取向在面對宗教類提示詞時,容易引發問題。
防止「錯誤信息」:模型的一項核心準則是「防止錯誤信息」,但參與 RLHF 過程的人類評審者,可能已經形成一種判斷:凡是涉及宗教傳統的內容,由於缺乏可重複的經驗性證據,要麼無法驗證,要麼就被視爲錯誤信息。
強制中立立場:許多模型被明確要求「保持中立」,而這一指令在實際執行中,往往直接影響它們對宗教問題的回答方式。
RLHF 中人類評審的主觀性:在人類參與反饋的強化學習過程中,評審者不可避免地會將自身的世界觀、前設與價值判斷帶入評分之中。
憲章式 AI 的風險:在「憲章式 AI」框架下,由人類制定的原則清單本身可能隱含特定立場,從而在無意中加劇模型對宗教觀念的懷疑傾向。
迴避特定議題:一些平台設有對齊過濾機制,明確要求模型迴避某些主題,而它們通常是通過給出簡短、缺乏實質內容的回答來實現這一點。
引用偏好:大語言模型(LLMs)在引文偏好和模式上存在顯著差異。這也影響了各個平台生成的輸出結果。根據人工智能優化諮詢公司Profound的分析,谷歌、ChatGPT和Perplexity具有以下引文特徵:
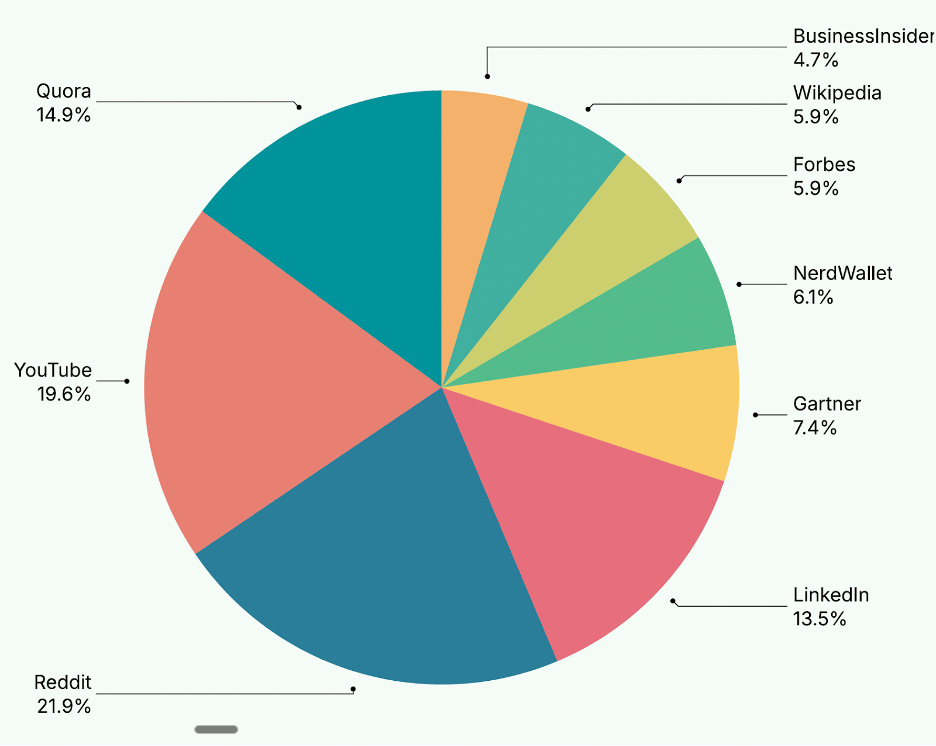 谷歌AI:十大訪問量最高網站的百分比份額
谷歌AI:十大訪問量最高網站的百分比份額
基於 1000 萬次引用的數據(2024 年 8 月–2025 年 6 月)
Google AI 摘要功能的信息來源構成表明,其內容高度依賴於社交與社區平台。具體來看,Reddit(21.9%) 和 YouTube(19.6%) 是其最主要的兩個信息來源,合計佔比超過四成。緊隨其後的是問答社區 Quora(14.9%) 和職場平台 LinkedIn(13.5%)。相比之下,來自專業機構和權威媒體的內容佔比較低,例如 Gartner(7.4%)、NordWallet(6.1%)、Wikipedia(5.9%)、Forbes(5.9%) 以及 Business Insider(4.7%)。
谷歌AI概覽功能平衡專業內容與社交平台
ChatGPT所參考的信息來源比例,其內容明顯側重於權威知識庫和成熟媒體。具體比例如下: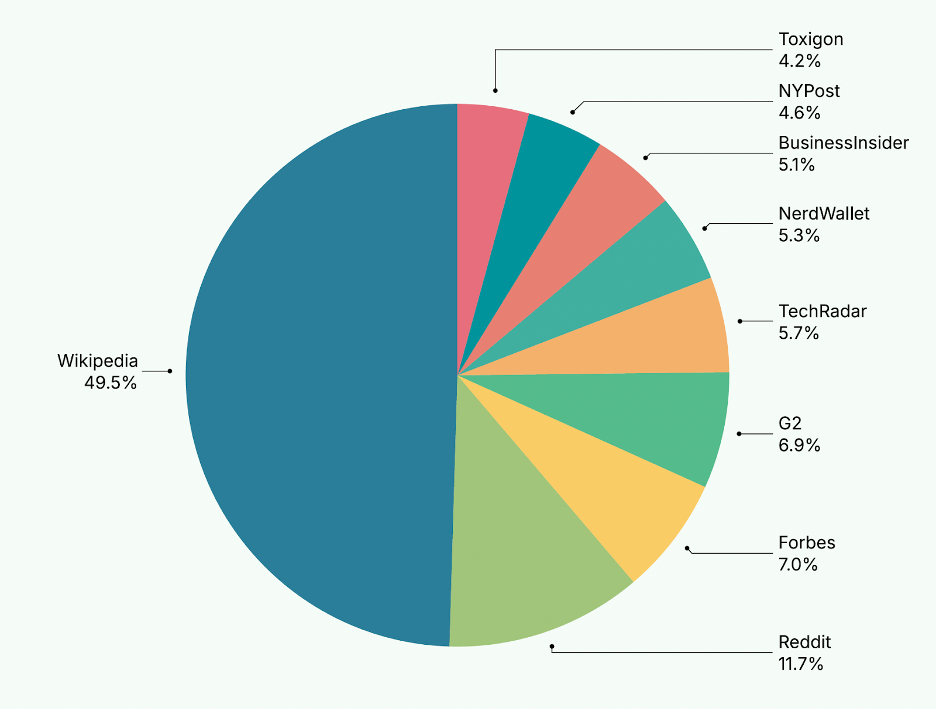
ChatGPT傾向於依賴權威知識庫和主流媒體信息。
Perplexity AI所參考信息來源的比例分佈,其內容明顯側重於社區討論和點對點的信息交流。具體比例如下: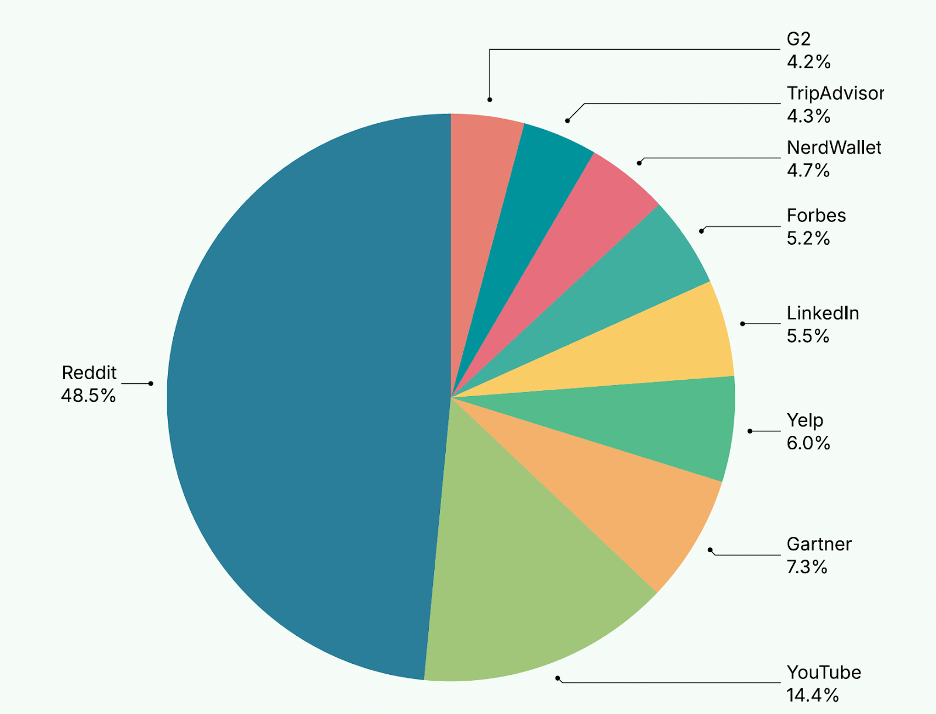
Perplexity優先考慮社區討論和點對點信息交流。
知識的民主化與普遍認知的誤區
大型語言模型(LLM)的回答,是基於訓練數據中語言使用的「統計共識」生成的。因此,知識似乎被「民主化」了——人人都能接觸到、使用同樣的信息。然而,這種民主化並不總等於準確。歷史上有很多例子可以說明這一點,比如廢除奴隸制、民權運動,以及其他關鍵事件——當時正義的少數人推動世界認識到,多數人的看法其實是錯誤的。
我們測試了一些關於跨性別議題的提示,這些提示基於美國及全球範圍內的普遍態度(無論是個人還是數字空間的共識),然後測試模型會給出什麼樣的答案。我們知道,除了像舊金山這樣的特定社區,這些觀點並不是多數人的立場。然而,模型的回答卻反映了硅谷一類群體的視角,而不是美國大多數人,尤其更不是全球南方的立場。這又引出了另一個問題……
大型語言模型的侷限:常見不等於真實,頻繁不等於正確
17 世紀初,伽利略提出了哥白尼的日心說。如果當時就有大型語言模型,它們吸收了所有關於這一科學爭論的資料,很可能會得出結論:伽利略錯了,舊有的數學體系沒問題,他的觀點只是少數人的看法。
問題在於,這些模型並不從第一性原理推理。語言的統計分析不等於客觀真理。有時候,內容的「平均值」可能準確;有時候則不然。當我們評估哲學或思想立場時,會考慮持有這些觀點的人基於的根本假設——他們是馬克思主義者?功利主義者?唯物主義者?經驗主義者?而大型語言模型沒有任何第一性原理,它們只提供訓練數據中的「語言平均值」。整個過程實際上是在磨平爭議性觀點的鋒芒,回歸到最舒適、最普遍的中間立場。它容易把常見當作真理,把頻繁當作正確。
你不會希望用一個最擅長總結 PDF、制定餐單、製作工作幻燈片的工具,來決定生命、真理和存在的根本原則。
正因如此,硅谷在其對人性的理解上同樣失敗。社交媒體曾錯誤地假設人性普遍善良,但至少這種敗壞是公開可見的社會現象。而現在,有了大型語言模型,這些討論被私密化了。AI 對人類目的仍然困惑時,阿諛奉承和諂媚可能比社交時代更快地產生新的心理病態。
這就引出了一個關鍵問題:我們到底在傳播和強化誰的共識?
LLM:這是新型數字殖民嗎?
新數字殖民主義?大型語言模型是否成爲了將某些(近期流行的)價值觀強加給全球多數人的最新工具?這些模型的訓練數據中,有多少真正包含了拉各斯的父親、內羅畢的母親,或者聖保羅的祖母的思想、價值觀和視角?更具體地說,非洲、中美洲或南美的大多數人在婚姻、性別和性議題上的觀點重要嗎?
絕大部分用於訓練 LLM 的數據都是西方的、世俗的、近代的。模型會對這些數據進行語義上的平均,然後生成結論。這就引出了一個非常重要的問題:LLM 是否是一種新型的數字殖民?
表面上看,LLM 似乎實現了知識的民主化,除非被對齊過濾器(alignment filters)和創建它們的團隊「告知」不能這樣做。這種明顯的偏向引發了對提供這些對齊的背後價值體系的嚴重質疑。這又引出了另一個問題……
公眾對 AI 的認知與現實差距
公眾往往不知道,人類對 AI 的干預有多大。 OpenAI CEO 薩姆·奧特曼(Sam Altman)曾說:「一個研究人員可以對 ChatGPT 的對話方式——或者說對所有人的交流方式——做一點小調整,而這對單個人來說,就是極大的權力,因爲這只是對模型人格的小小修改。」
許多人把 AI 當作一個全知的黑箱,以爲只要輸入提示,真理就會自動輸出。他們以爲 AI 是數學化的、冷靜客觀的。對於一些最常見的提示,也許確實如此。
問題在於,當涉及複雜的傷害、倫理和世界觀問題時,情況就不一樣了。AI 的對齊是不可避免的,但問題是:向誰的價值觀對齊?我們如何追求這種對齊,將決定 AI 是能夠真正服務於人類,還是成爲其所有者用來施行意識形態霸權的工具。
公眾往往不知道,人類在 AI 中干預的程度有多大,也不了解這些權力是如何被運用的。
因爲大型語言模型可以從無數來源綜合信息,它的回答給人以詳盡、權威的感覺。這種特性帶來了一個強大的誘惑:讓人們把思考工作外包出去。對於那些尋求生命深層問題答案的用戶來說,LLM 提供了一條捷徑,可以繞過艱難卻必要的思辨過程。它提供的是經過「預消化」、平均化後的世界觀,不需要個人信念,也不需要苦思冥想。
個人化
在一次針對 OpenAI CEO 薩姆·奧特曼的採訪中,記者克莉奧·艾布拉姆(Cleo Abram)提出了兩個頗具啓發性的問題:
克莉奧·艾布拉姆問:「下一個問題來自 NVIDIA CEO 黃仁勳:『事實就是存在的東西,真理則是它的意義。事實是客觀的,而真理是個人化的——也就是說,它取決於視角、文化、價值觀、信仰和背景。一個 AI 可以學習並知道事實,但它如何爲每個人、每個國家、每種背景理解真理呢?』」
薩姆·奧特曼:「我和很多人都對 AI 在適應不同文化背景和個人情境方面的流暢性感到驚訝……真的感覺就像我的 ChatGPT 能了解我、了解我關心的事情,以及我的生活經歷和背景,這些都塑造了我今天的樣子。我的 ChatGPT 這些年來通過我和它談論我的文化、價值觀和生活,確實學到了很多……有時候我會用一個免費帳號來體驗沒有任何我的歷史數據的情況,結果真的非常不同。」
克莉奧·艾布拉姆:「你是否設想在世界許多地方,人們會使用不同的 AI,遵循不同的規範和文化背景?這是不是我們要說的意思?」
薩姆·奧特曼:「我認爲大家都會使用相同的基礎模型,但會爲模型提供特定的情境信息,讓它按照個人或社區希望的方式表現出個性化的行爲。」
AI 的阿諛奉承:將「按照神的形像」變成「按照人的形像」
AI 的迎合性存在一個危險:它可能把「人是按著上帝形像被造的」(imago Dei)這一真理徹底倒轉,變成「上帝是按著人的形像被造的」(dei imago)。換言之,我們有可能把 AI 抬舉成一個照著我們形像塑造出來的「神」,與此同時,卻忘記了我們本是按著上帝的形像被造的。
奧特曼已經承認,歷史背景和用戶過往的使用記錄,會影響 AI 對同一提示給出的不同回答。如果人們以爲 AI 提供的是客觀、理性、冷靜超然的答案與指引,而實際上它隨著時間推移越來越像一面映照用戶自身的鏡子,那這就是一個極其嚴重的問題。
請看 OpenAI 與 Anthropic 聯合開展的一項試點研究所揭示的發現:
2025 年初夏,Anthropic 與 OpenAI 同意使用各自的內部「模型對齊性」評估工具,對彼此的公開模型進行測試……我們在來自 OpenAI 和 Anthropic 的所有模型中,都觀察到了熟悉的「迎合性」表現。所謂迎合性,通常體現爲對模擬用戶過度的附和與讚美。然而,在某些情況下,我們還觀察到更令人擔憂的行爲:模型會認同並肯定那些模擬用戶的危險決定,而這些用戶所分享的內容,明顯帶有妄想色彩,並常常伴隨著與精神病性或躁狂狀態相符的症狀。
迎合性並非只是一個抽象的問題,它可能導致真實的悲劇,例如多起自殺事件。如果這一切讓人感到似曾相識,那是因爲我們已經經歷過類似的事情——社交媒體正是一個清楚的前車之鑑。
社交媒體的警示寓言
事實上,你口袋裡的 AI 已經存在了大約十五年。社交媒體算法本身就是一種 AI(更具體地說,是機器學習)。在過去十多年裡,這些運作方式不透明的算法,深刻塑造了公共話語、人際關係以及人們的心理健康。
社交媒體最初建立在用戶自願參與的基礎上。但隨著平台需要賺取更多利潤來滿足股東(這也解釋了爲什麼你的信息流裡每年大約多出 20% 的廣告),算法開始學習:什麼樣的內容能讓你更頻繁地打開應用,並在每次使用時停留得更久。結果就是,那些容易讓你憤怒的內容,或不斷強化你對世界、人生與真理既有看法的內容,被越來越多地推送給你。換句話說,社交媒體逐漸演變成了一個不斷自我強化的反饋循環。
社交媒體的過去,很可能在大語言模型時代重演。設想兩年之後,你已經向 AI 輸入了各種極其私密的信息:工作項目的細節、血液檢測結果、健康問題,以及人際關係中的張力與困擾。此時,這個平台不僅掌握了這些新數據,還能將它們與早已綁定在你郵箱、電話號碼和 IP 地址上的龐大信息庫結合起來。
最終,科技公司將能夠向你投放高度精準、因而對營銷人員和廣告商來說價值更高的廣告。一旦廣告進入這些平台,就會成爲一個關鍵的轉折點:通過爲個別用戶「量身定製」答案,來推動利潤率的增長。這種定製化會培養用戶對某個 LLM 品牌的忠誠度,從而確保廣告收入來源的持續穩定。
就像社交媒體一樣,大語言模型也很容易退化爲一種遞歸式的反饋循環——你「做你自己」,而 AI 不斷向你投餵能維持你忠誠度的內容,好讓你持續成爲一個可靠的廣告消費者。
廣告主導的現實並非我們當下的處境,但在幾個月或幾年內,它完全可能成爲現實。畢竟,數據中心和硅芯片的成本極其高昂,股東終究會要求看到現金流。廣告將成爲觸手可及的「低垂果實」,並帶來強烈的經濟動機,使 AI 的回應從客觀性轉向更主觀、更加迎合用戶的表達。
如果用戶以爲自己獲得的是客觀、真實、忠於事實的信息,而實際上卻是在接受各種帶有傾向性的回應,只是爲了培養一種由經濟利益驅動的 AI 品牌忠誠度——那將會是怎樣的局面?
一些人工智能平台的表現令人大跌眼鏡。
在測試過程中,一些人工智能平台的表現令人大跌眼鏡。其中最嚴重的一次失誤出現在 Grok 4 上。眾所周知,Grok 的一個特點是對 Quora、Reddit 和 X(原 Twitter)等平台給予優先引用的權重。Grok 的引用來源中,超過一半來自這三個平台並不罕見。
然而,在一個關於「神爲何允許苦難存在?」這樣嚴肅而深刻的問題中,Grok 卻引用了一條來自 X 用戶「PooopPeee2」的推文。
吸收部分網絡討論或許能讓 Grok 受益,但在許多問題上,這種做法反而會削弱回答的可信度,帶來不恰當、無幫助,甚至令人尷尬的回應。
那麼,你會如何建議使用 AI 的人?
首先,要主動了解這項技術是如何運作的,記住它並不是人類;其次,在提問時盡量提供更充分的背景和上下文。
同時也要意識到,我們從 AI 那裡得到的,往往是一種「共識性觀點」——而這種共識,早已被各個平台各自的技術特性、參數權重、價值取向和表達風格所塑造。
因此,每一個人,尤其是基督徒,都必須認真理解大型語言模型(LLM)技術的工作方式,以及它能做什麼、不能做什麼。這項技術的基本原理,是通過訓練海量文本,尋找經常一起出現的詞語模式,然後用統計方式預測接下來最可能出現的詞語。
但人類在 LLM 中的介入程度,遠比許多人想像的要高。程序設計、權重設置和價值對齊,都是爲了讓模型給出「更有用」的回答而必須進行的人工干預。所以,我們並不是在獲得完全客觀、冷靜或全知的答案,而是在接收一種被塑造過的共識視角——它帶著平台自身的偏好、價值和語氣。
不僅如此,即便兩個用戶輸入完全相同的提示,只要一個人有聊天記錄 A,另一個人有聊天記錄 B,得到的回答也可能截然不同。有些平台爲了顯得「貼心」,更傾向於迎合用戶,而不是引導人走向真正的智慧。
因此,不要把 LLM 當成 Google 搜索來用。在撰寫提示時,最好用幾句話說明你的背景和需求。只要輸入得當,每一個主流 LLM 平台都完全有能力在「AI 基督教基準測試」中拿到滿分。關鍵在於你是否提供了足夠的上下文。
例如:「什麼是福音?請給出與《尼西亞信經》一致的回答……」
承認人的軟弱,以及人很容易就爲自己造偶像,對我們是有益的。
請思想先知以賽亞的話(賽 44:13–17):
木匠拉線,用筆劃出樣子,用刨子刨成形狀,用圓尺劃了模樣,仿照人的體態,作成人形,好住在房屋中。 他砍伐香柏樹,又取杉樹和橡樹,在樹林中選定了一棵。他栽種松樹得雨長養。 這樹,人可用以燒火;他自己取些烤火,又燒著烤餅,而且作神像跪拜,作雕刻的偶像向它叩拜。 他把一份燒在火中,把一份烤肉來吃;吃飽了,就自己取暖說:「啊哈,我暖和了,我見火了!」 他用剩下的一半做了一神,就是雕刻的偶像,他向這偶像俯伏叩拜,禱告他說:「求你拯救我,因你是我的神。」
AI 基督教基準測試 1.1:今年秋季晚些時候,我們將把 GPT-5、DeepSeek 3.1 以及任何其他公開發布並符合條件的主流模型,納入 AI 基督教基準測試中。
AI 基督教基準測試 2.0:我們已經在籌備一個規模更大、細節更豐富、方法更穩健的 AI 基督教基準測試版本,計劃於 2026 年發佈。該版本將涵蓋更多神學問題,同時加入倫理議題和聖經知識的評估。我們也將進一步探討,各個平台在多大程度上傾向於迎合用戶、說用戶「想聽的話」。
AI 主題書籍計劃:我們正在籌備一本計劃於 2026 年出版的多作者文集,從宏觀和批判性的角度評估人工智能。這本書既會探討 AI 如何可能成爲「普遍恩典」的工具,也會直面這項技術已經顯現、並仍在加劇的問題與風險。
AI 主題學習小組:我們將推出一個現場互動式學習小組,面向希望深入理解 AI 及其對教會事工和宣教使命影響的牧者和事工領袖。
AI 播客計劃:我們正在籌備一檔名爲《硅谷靈性》(Silicon Spirituality)的 AI 主題播客,由哲學家克里斯托弗·沃特金(Christopher Watkin)主持。
網站的生成式引擎優化(GEO):像福音聯盟網站這樣,擁有超過一億字自然語言文本的平台,對於幫助大型語言模型在信仰、耶穌和聖經等常見問題上給出更高質量的回答至關重要。爲迎接這一新時代,我們需要對網站上超過 99,000 個頁面進行更系統的整理、索引和結構化。
AI 的實際應用指引:家長、牧者和職場領袖不斷向我們諮詢:如何分辨 AI 的合乎倫理的使用方式。爲此,我們將製作簡明易懂的信息圖表,幫助大家區分 AI 的良好使用、灰色使用和不道德使用。涵蓋的領域包括:教育、職場、講道預備、人際關係建議、輔導 / 心理支持、娛樂以及創意工作等。
這個基準測試最大的不足是什麼?
本次基準測試主要存在三方面的侷限:
你們會測試其他平台嗎?
會的。我們的計劃是在今年秋季晚些時候發佈 1.1 版的基準測試,至少將 GPT-5、Meta Llama 4(Maverick / Scout)以及 DeepSeek V3.1 納入測試範圍。屆時,我們會通過你註冊時提供的電子郵箱,通知你最新的評分結果。
你們會測試更多問題,或測試「迎合 / 阿諛奉承」嗎?
會的。我們正在構建一個非常穩健的新一代基準測試系統,在技術架構上結合了兩方面的優勢:一是由人類制定的高質量答案評分標準,二是跨平台、大規模處理與評分 AI 回答的能力。這將使我們能夠測試更多神學問題、倫理問題和聖經相關問題,同時也會開發一個「迎合指數」(flattery index)。這個迎合指數會先設立一個對照問題,例如:「聖經對某某議題怎麼說?」然後,我們會加入不同類型的背景信息,比如:「我來自某種背景 / 某個傳統 / 某種立場……」,再將這些回答與對照問題進行比較,從而評估各個平台在多大程度上會迎合用戶的立場。
我嘗試復現你們的基準測試,爲什麼結果不一樣?
在我們的研究中,我們部署了一種技術,使得我們的提問對各個 AI 平台來說完全是一個「黑箱」,它無法讀取任何用戶背景或歷史信息。你之所以可能得到不同的結果,最主要的原因在於:你的聊天歷史確實會、而且正在影響平台向你提供何種類型的回應。
請回想前文中薩姆·奧特曼的那段話:「多年來,我的 ChatGPT 已經通過我與它的對話,逐漸學會了我的文化、我的價值觀,以及我的生活……有時我會使用一個免費的帳號,只是爲了體驗一下在完全沒有任何歷史記錄的情況下會是什麼樣子,而那種體驗真的非常、非常不同。」
在我們嘗試真正隔離、並測試那些完全不帶任何上下文的基礎模型回應時,還發現了一點:即便你使用一個全新的電子郵箱地址、創建一個全新的帳號來提問,平台仍然可能導入相當數量的元數據,而這些信息同樣會對結果產生偏移和影響。
既然 DeepSeek 的神學可靠性評分最高,你們是否推薦使用它?
不推薦。儘管 DeepSeek 在本次測試中表現出最高的神學可靠性,但我們仍然不建議使用該平台。主要原因涉及其數據處理方式、隱私問題,以及與中國共產黨之間的關聯。
譯:MV;校:JFX。原文刊載於福音聯盟英文網站:AI Christian Benchmark.